

Qu’est-ce que l’apprentissage supervisé ?
L’apprentissage supervisé est une méthode d’apprentissage automatique, caractérisée par la création d’un algorithme qui apprend une fonction prédictive. Ceci est possible grâce à un entrainement à partir d’exemples annotés, qui inclus un groupe de variables d’entrée, accompagnées de leurs variables de sortie respectives. Ce processus d’entrainement est répété jusqu’à l’obtention d’une performance satisfaisante. Lors de chaque itération, la machine crée un certain nombre de règles, reliant les variables d’entrée aux variables de sortie. Ce processus permet au modèle d’apprendre à partir des données et d’appliquer les règles afin prédire, de façon précise, la valeur de sortie lorsqu’une valeur d’entrée est donnée.
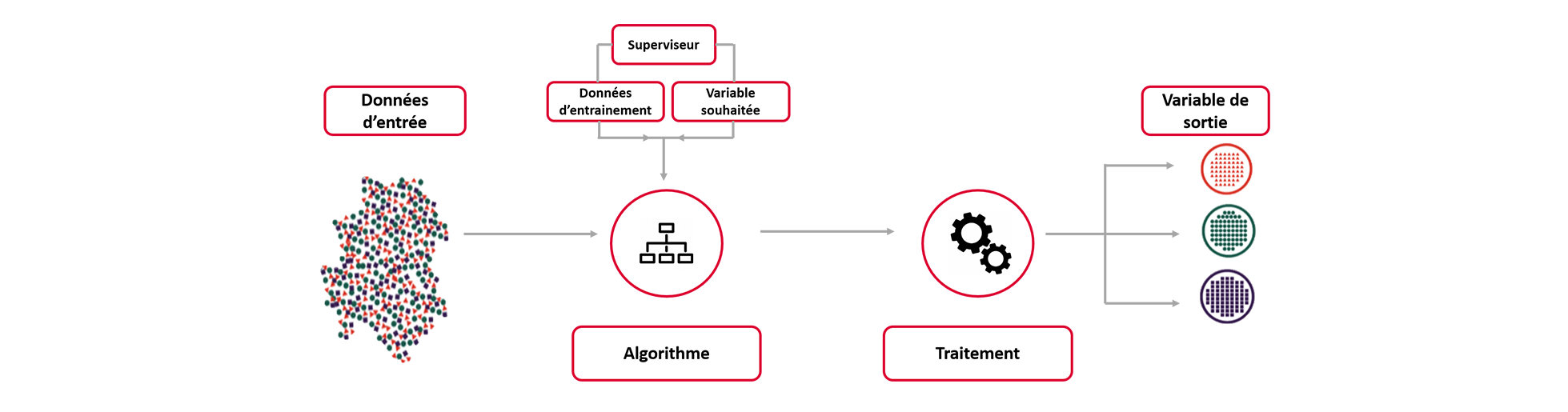
L’apprentissage supervisé peut être divisé en deux sous-catégories : la classification et la régression. Nous allons maintenant nous concentrer sur cette dernière. Pour plus d’information sur les modèles de régression, la classification ainsi que l’utilisation de ces techniques par Linedata, veuillez consulter les prochains articles.
Régression
Contrairement à la classification qui prédit une catégorie ou une étiquette, les modèles de régression prédisent une valeur de sortie continue, en fonction de la variable indépendante d’entrée. Cette technique est utilisée lorsque la variable de sortie à prédire doit être une valeur continue, soit par exemple pour les prédictions météorologiques ou pour les tendances de marché. Différents modèles de régression existent et diffèrent dépendant de la relation entre le variable dépendante et indépendante considérées, ainsi que du nombre de variables indépendantes utilisées pour le modèle. Parmi les principaux modèles de regression, on trouve la régression linéaire simple et multiple, la régression de Poisson et la régression à vecteurs de support (ou Support Vector Regression, SVR).
Ainsi, l’analyse de régression est une forme de statistique inférentielle, utilisée pour identifier des tendances au sein des données. Il existe différents algorithmes de régression, partageant le même but qui est de déterminer une valeur de sortie continue en fonction d’une variable d’entrée indépendante.
Un cas d’usage de l’apprentissage supervisé

Pour plus d’informations, veuillez consulter l’article « Bank of America brings AI to equity capital markets » du 2 mars 2020.
Nous espérons que cet article vous aura fournis des informations contextuelles sur le sujet de l’apprentissage supervisé et sa catégorie de régression. Dans l’article suivant, nous explorerons les principaux algorithmes utilisés pour la régression supervisée ainsi que un exemple de cas d’usage chez Linedata.