Dans les dernières années, Linedata a implanté des algorithmes de machine learning dans ces solutions de front-office et de back-office. Dans les articles précédents, nous nous sommes concentrés sur l’apprentissage supervisé ainsi que sur les différents algorithmes qui peuvent être utilisés pour des modèles de régression. Dans cet article, nous allons nous focaliser sur la prédiction d’erreur de transaction, qui constitue l’une des applications d’apprentissage supervisé de la compagnie.
L’utilisation de la régression supervisée chez Linedata
Chez Linedata, nous utilisons diverses méthodes de machine learning qui sont implantées dans nos produits. L’une des applications les plus importante de la régression est pour la prédiction d’erreur de transaction.
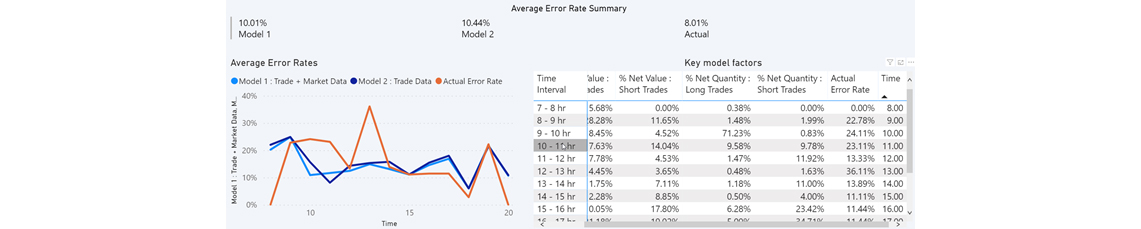
Lorsque l’on souhaite comprendre l’analyse post-transactionnelle d’un système, il y a souvent des données disponibles qui informent sur l’entièreté de l’historique de transaction. En utilisant ces données, nous pouvons visualiser les transactions précédentes, qui ont été entrées dans le système, et identifier celles qui ont été modifiées (manuellement) et celles qui ne l’ont pas été. Parmi ces révisions, on peut inclure les changements de quantité et de prix ou les changements du fond auquel la transaction est liée. Ces modifications peuvent être dues à des erreurs opérationnelles ou humaines, comme par exemple la modification manuelle d’un prix à cause d’une actualisation incorrecte des prix ou d’une erreur humaine dans la transaction initiale. De surcroît, en utilisant l’heure exacte de la transaction initiale, il est possible d’identifier le nombre de transactions, qui en moyenne, furent modifiées au cours de d’une plage horaire : c’est ce qu’on appelle le taux d’erreur. Pour ceci, nous groupons les données par créneaux horaire, ce qui produit des observations utilisables pour l’analyse du taux d’erreur et des activités de transactions lors de ces créneaux.
Sur la base de ces éléments, nous avons construit un modèle d’apprentissage supervisé afin de prévoir le taux d’erreur, soit notre variable à expliquer. Les variables prises en compte dans ce modèle sont : les quantités horaires cumulatives, la proportion de valeurs pour cet horaire en comparaison avec la journée entière, ainsi que les taux d’erreur des jours précédents. Ceci correspond à une analyse chronologique qui examine l’entièreté des données sur 10 ans et qui retarde chaque heure de la journée afin d’apporter des variables additionnelles, de telle sorte à ce que les données de transactions des jours précédents puissent influencer les jours à venir.
Afin de construire ce modèle dans Python, nous avons utilisé la méthode extra-trees de la librairie sklearn. Le modèle de regression de extra-trees est basé sur un arbre de décision. En effet, il établit un méta-estimateur qui évalue un certain nombre d’arbres de décision aléatoires, soit des extra-trees, sur différents échantillons de données et qui utilise une moyenne pour améliorer la précision de la prédiction et contrôler la généralisation.
Pour en savoir plus sur les arbres de décision, veuillez consulter les prochains articles sur les algorithmes de classification.
A venir
Nous espérons que cet article vous aura permis de comprendre l’utilisation de la régression chez Linedata.
Si vous souhaitez en savoir plus sur la classification, soit la deuxième méthode d’apprentissage supervisé, veuillez consulter les prochains articles..