La classification est l’une des méthodes d’apprentissage supervisé, qui permet de restituer une valeur à expliquer discrète, comme une classe ou une étiquette. Ainsi, le modèle est entrainé de telle manière à rendre une valeur discrète (y) en fonction d’une valeur d’entrée (x).
Dans l’article précédent, nous nous sommes focalisés sur les mesures d’évaluation pour les modèles de classification, qui permettent d’évaluer la qualité de la performance d’un modèle.
Maintenant, nous allons explorer les principaux algorithmes de classification, incluant la méthode des K plus proches voisins, les arbres de décision, et les forêts d’arbres décisionnels. Il existe une deuxième partie à cet article, qui se concentre sur la régression logistique et la classification naïve bayésienne.
Principaux algorithmes
1.a. Méthode des K plus proches voisins (on K-nearest neighbors, KNN)
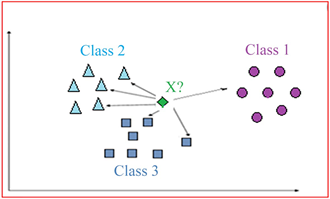
La méthode des K plus proches voisins est l’un des algorithmes d’apprentissage supervisé, qui peut être utilisé pour un problème de régression et de classification. Cependant, elle reste principalement utilisée pour les problèmes de classification. Cet algorithme s’entraine sur des données étiquetées et tente de prédire la classe associée à des variables d’essai, en calculant la distance entre la variable d’essai explicative et les points d’entrainement. En d’autres termes, cette méthode enregistre les points d’entrainement puis classifie les nouveaux points dépendant de leur similarité avec les données enregistrées.
Ci-dessous, vous trouverez un exemple de méthode avec trois voisins. Le but étant d’identifier à quelle classe appartient le point X.
L’algorithme pour les modèles des K plus proches voisins est le suivant :
1. Choisir le nombre K de voisins
2. Calculer la distance Euclidienne des K voisins
3. Prendre les K plus proches voisins, dépendant du résultat du calcul de la distance
4. Parmi ce K voisin, compter le nombre de points dans chaque classe
5. Attribuer le nouveau point à la classe dont le nombre de voisins est maximal
6. Le modèle est terminé
La distance euclidienne peut être calculée de la manière suivante :
où et sont des vecteurs avec p éléments. La distance euclidienne est un cas particuler de la distance avec q = 2.
1. b. Arbre de décision
Un arbre décisionnel est un outil de modélisation prédictive qui peut être utilisé aussi bien pour la régression que pour la classification. Dans le cas d’un arbre décisionnel de classification, la variable de décision est une catégorie, alors que dans le cas d’un arbre décisionnel de régression, la variable de décision est continue. Les arbres de décision sont probablement l’un des algorithmes de machine learning les plus compréhensibles et peuvent être interprétés de manière relativement simple. Ces arbres peuvent être construit à travers une approche algorithmique qui sépare les données, dépendant de différentes conditions. Dans un arbre, les feuilles (ou nodes) représentent les valeurs de la variable-cible et les embranchements correspondent à une combinaison de variables d’entrée menant à ces valeurs.
La création d’un arbre décisionnel nécessite les étapes suivantes :
1. Choisir une variable de prédiction qui classifie les données de la meilleure manière et qui attribue chaque point à la première feuille.
2. Descendre le long de l’arbre, en partant de la première feuille, tout en prenant des décisions par rapport à la classification de chaque point
3. Retourner à l’étape 1 et répéter ce même processus jusqu’à ce que chaque point soit classifié.
Afin d’évaluer les séparations au sein d’un arbre, nous pouvons utiliser le coefficient de Gini. Cette fonction peut prendre en compte des variables discrète et est calculée de la manière suivante :
où correspond à la probabilité d’un élément d’être classifier dans une classe particulière.
Lors de la mise en place d’un arbre, notre but est de choisir les variables avec un coefficient de Gini le plus proche de celui de la première feuille.
Une autre méthode pour séparer les données est le information gain. En effet, cette méthode est utilisée pour déterminer quelle variable nous donne le maximum d’information sur une classe. Elle utilise le concept d’entropie, qui mesure l’incertitude dans les données et est utilisé pour déterminer comment diviser les données dans un arbre décisionnel. Les formules pour ces deux mesures sont les suivantes :
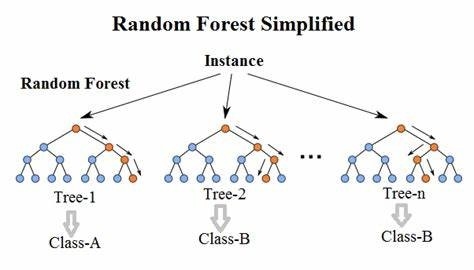
1.c. Forêt d’arbres décisionnels
Nous venons de comprendre le fonctionnement d’un arbre décisionnel. Nous pouvons maintenant examiner l’algorithme de forêt d’arbres décisionnels. En effet, une forêt d’arbres décisionnels est un algorithme d’apprentissage supervisé, qui peut être utilisé pour la régression et la classification. Ce genre d’algorithme peut créer un ensemble d’arbres décisionnels aléatoires, à partir d’un groupe de données. L’algorithme identifie la meilleure prédiction au sein de chaque arbre et sélectionne la meilleure décision par le biais d’un vote. Ainsi, cela nécessite plusieurs arbres produisant des valeurs, qui réduisent le sur apprentissage de l’algorithme en faisant une moyenne des résultats.
L’algorithme de forêt d’arbres décisionnels peut être résumé par les étapes suivantes :
1. Sélectionner un échantillon aléatoire parmi les donné est
2. Construire un arbre de décision pour chaque échantillon et obtenir des prédictions pour chaque arbree
3. Un vote est réalisé pour chaque prédiction obtenue
4. Sélectionner la prédiction avec le plus grand nombre de voix, comme étant la prédiction finale.
Exemple : Forêt décisionnels à trois arbres
Il a été démontré que les algorithmes de forêt d’arbres décisionnels ont la plus haute efficacité pour la détection de fraudes, en comparaison à d’autres modèles. En effet, dans une étude réalisée par Dal Pozzolo et al (2014), les auteurs analysent la détection de fraudes sur des cartes bancaires et comparent différents algorithmes. Les résultats montrent qu’un modèle basé sur une forêt d’arbres décisionnels surpasse, au niveau de l’AP, de l’AUC et du Precision Rank metrics, une machine à vecteurs de support et un réseau neuronal convolutif.
A venir
Nous espérons que cet article vous aura donné une bonne compréhension des trois premiers algorithmes de classification ainsi que de leurs utilisations.
L’article suivant correspond à la deuxième partie de cet article et se concentre sur la régression logistique et la classification naïve bayésienne.
Référence
Dal Pozzolo, A., Caelen, O., Le Borgne, Y. A., Waterschoot, S., & Bontempi, G. (2014). Learned lessons in credit card fraud detection from a practitioner perspective. Expert Systems with Applications, 41(10), 4915 4928. https://doi.org/10.1016/j.eswa.2014.02.026



 et
et  sont des vecteurs avec p éléments. La distance euclidienne est un cas particuler de la distance
sont des vecteurs avec p éléments. La distance euclidienne est un cas particuler de la distance  avec q = 2.
avec q = 2.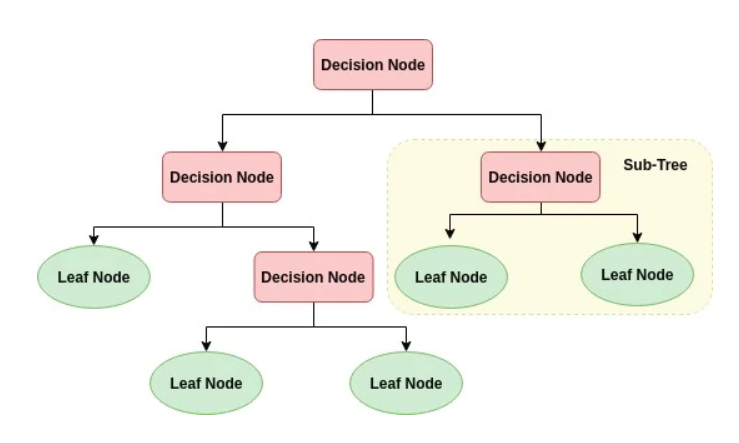

 correspond à la probabilité d’un élément d’être classifier dans une classe particulière.
correspond à la probabilité d’un élément d’être classifier dans une classe particulière.