Bienvenue à notre deuxième article sur les algorithmes de classification. Précédemment, nous avons explorer les différentes mesures d’évaluation pour les modèles de classification ainsi que trois des principaux algorithmes : la méthode des K plus proches voisins, les arbres de décision et les forêts d’arbres décisionnels.
La classification est un outil très puissant et utile dans le domaine de l’apprentissage supervisé. Il est donc important de détailler deux autres de ses algorithmes : la régression logistique et la classification naïve bayésienne. Nous allons les explorer ci-dessous.
2. a. Régression logistique
La régression logistique est une technique de classification linéaire, qui est utilisée afin de prédire la probabilité d’une variable-cible et d’établir une relation linéaire entre la variable d’entrée et celles de sortie. De manière générale, la variable explicative est binaire et est donc représentée par à 1, lors d’un succès/oui, ou par un 0, lors d’un échec/non. Cependant, il peut y avoir plus de deux catégories de variable explicatives : cela nécessite alors l’utilisation d’une régression logistique multiple.
i) Régression logistique binaire
La régression logistique binaire constitue la forme de régression logistique le plus répandue et utilisée. Elle implique une variable explicative prenant seulement deux valeurs : 1 ou 0.
Etant donné que la régression logistique est un modèle linéaire, la fonction d’hypothèse suivante peut être utilisée :
Si on attribut la valeur =1, alors la formule précédente devient :
Dans ce cas, X correspond à un vecteur de
De la même manière, si on écrit ϑ comme étant le vecteur alors on peut réecrire la formule précédente comme : S (X)= ϑX.
Cette fonction d'hypothèse se nomme la fonction score. Idéalement, on souhaite que soient tel que :
S(X)>0 lorsque la variable explicative est 1
S(X)<0 lorsque la variable explicative 0
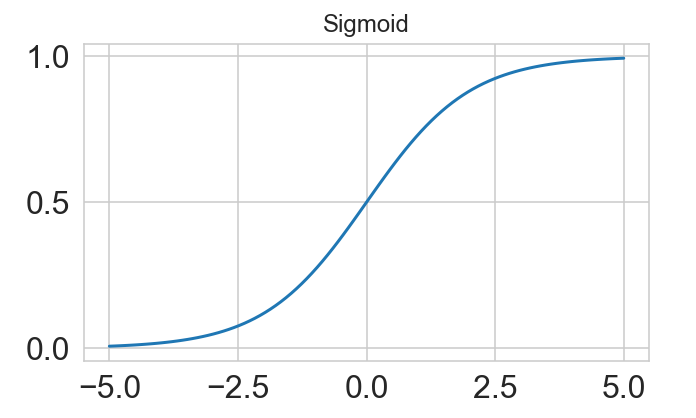
Dès lors, en utilisant la fonction score, on peut calculer la fonction sigmoïde, ou courbe en S, qui est utilisée pour les modèles de régression logistique. Cette fonction rend des valeurs entre 0 et 1 et ce résultat peut être interprété comme la probabilité qu’une observation X corresponde à la valeur à expliquer de 1. Lorsqu’on applique la fonction sigmoïde sur notre fonction score, on obtient une fonction d’hypothèse, pour notre modèle , de la forme suivante :
Ainsi, cela correspond à la probabilité qu’une observation X soit de classe 1, avec pour paramètre ϑ. De manière équivalent, la probabilité que X soit de classe 0 est donné par :
Le graph suivant représente la fonction sigmoïde précédente :
ii) Régression logistique multiple
Dans ce type de classification, la variable explicative peut prendre trois ou plus valeurs possibles. Par exemple , on peut avoir une variable de « Type A », de « Type B » ou de « Type C ». La variable explicative serait de forme non-ordonnée, ce qui implique que les valeurs n’auraient pas de signification quantitative. La formule précédente, présentée dans la régression logistique binaire, peut être adaptée pour la version multinomiale.
2. b. Classification naïve bayésienne
La classification naïve bayésienne est une méthode d’apprentissage supervisé, qui repose sur le théorème de Bayes et l’hypothèse que toutes les variables explicatives sont indépendantes les unes des autres. En d’autres termes, l’hypothèse implique que la présence d’une variable dans une classes est indépendante de la présence d’une autre variable dans la même classe. Ainsi, toutes modifications à l’une des variables ne devraient pas directement impacter la valeur d’une autre variable de ce modèle.
La classification naïve bayésienne nécessite l’entrainement du modèle, comme pour tout algorithme d’apprentissage supervisé, afin d’estimer les paramètres nécessaires à la classification. L’intérêt d’utiliser cette méthode est de trouver la probabilité d’une classe, ou d’une étiquette, en fonction de certains paramètres. On appelle ceci la probabilité postérieure, qui peut être calculée avec la formule suivante :
où :
Y est l’ensemble des paramètres et X est l’ensemble des observations
P(X|Y) est la probabilité postérieure d’une classe et est donné par :
P(X) est la probabilité antérieure d’une classe
P(Y|X) est la probabilité d’un indicateur, connaissant la classe. Elle est donnée par :
P(Y) est la probabilité antérieure d’une variable dépendante.
Le modèle naïf bayésien est généralement utilisé pour la classification de documents, le filtrage des spam et les prédictions.
Il existe différentes versions du modèle naïve bayésien, comme la Gaussian Naïve Bayes , Bernoulli Naïve Bayes, et Multinomial Naïve Bayes. Nous allons maintenant comprendre la version de Gaussian Naïve Bayes.
i) Gaussian Naïve Bayes
Gaussian Naïve Bayes est une extension de la classification naïve bayésienne, avec la spécificité que X suit une distribution particulière, soit la distribution normale ou gaussienne. Ainsi, on peut utiliser la fonction de probabilité et cette distribution afin de calculer la probabilité d’un évènement. Pour cela, nous devons connaitre la moyenne et la variance de X et utiliser la formule suivante :
où :
σ représente la variance de X et μ représente la moyenne de X X
c représente une classe de Y
A venir
Nous espérons que ces articles vous auront donné une bonne compréhension des cinq principaux algorithmes de classification.
Avec toutes ces informations, on remarque que différentes applications nécessitent différents algorithmes, dépendant des critères du problème en question.
Chez Linedata, nous sommes en train d’incorporer des techniques de classification dans nos produits, afin de prédire des scores d’erreurs de transaction. Pour plus d’information, veuillez consulter le prochain article.



 =1, alors la formule précédente devient :
=1, alors la formule précédente devient :

 alors on peut réecrire la formule précédente comme :
alors on peut réecrire la formule précédente comme :