

L’apprentissage supervisé est une technique de modélisation prédictive qui se caractérise par l’entrainement d’un modèle à partir de données d’entrainement étiquetées, incluant un groupe de variables explicatives et leurs variables à expliquer respectives. Ceci permet au modèle d’établir des règles entre les variables d’entrée et celles de sortie, afin d’associer une nouvelle variable d’entrée non-étiquetée à une variable de sortie.
L’apprentissage supervisé peut être divisé en deux sous-catégories : la régression et la classification. Dans un article précédent, nous nous sommes focalisés sur les modèles de régression, tels que la régression linéaire simple et multiple, la régression de Poisson et la régression à vecteurs de support.
Maintenant, nous allons explorer la méthode de classification ainsi que les différentes mesures d’évaluation, utilisées pour les modèles de classification. Si vous souhaitez en savoir plus sur les différents algorithmes de classification et leurs utilisations chez Linedata, veuillez consulter les articles suivants.
Classification

Par exemple, si on souhaite prédire le prix d’une voiture, l’utilisation d’un modèle de classification nous permettrait de classifier cette voiture au sein d’une gamme de prix prédéterminés. Par ailleurs, l’utilisation d’un modèle de régression permettrait de prédire la valeur exacte de la voiture.
Dans le cas où seulement deux classes peuvent être restituées par le modèle, on parle de classification binaire. D’autre part, si plus de deux classes peuvent être restituées par le modèle, alors on parle de classification en classes multiples.
Les modèles de classification sont le plus communément utilisés pour la classification d’images, la classification de documents, le traitement automatique de langage naturel (ou NLP) ou encore pour la détection de fraude.
Mesure d’évaluation pour les modèles de classification
Une fois que un modèle a été déterminé et implanté, il est important d’établir la qualité de ce modèle. Pour cela, diverses mesures d’évaluation peuvent être utilisées et choisies soigneusement, puisque le choix de la mesure peut influencer la manière dont la performance est évaluée et interprétée.
L’une des manières les plus répandues pour mesurer la performance d’un modèle de classification est la matrice de confusion. Cette dernière correspond à un résumé tabulaire du nombre de prédictions correctes et non correctes, faites par le modèle. Dans cette matrice, chaque ligne correspond à une classe réelle et chaque colonne correspond à une classe estimée.
Elle inclut les valeurs suivantes :
- Vrais positifs (ou True Positive, TP) soit lorsque la classe réelle et la classe estimée sont toutes les deux positives
- Vrais négatifs (ou True Negative , TN) soit lorsque la classe réelle et la classe estimée sont toutes les deux négatives
- Faux positifs (ou False Positive, FP) soit lorsque la classe réelle est négative mais que la classe estimée est positive. On appelle ceci une erreur de Type 1.
- Faux négatifs (ou False Negative, FN) soit lorsque la classe réelle est positive mais que la classe estimée est négative. On appelle ceci une erreur de Type 2.
Dans le cas d’une classification binaire, la matrice de confusion sera une matrice de 2 par 2, avec quatre valeurs, comme dans la photo suivante :
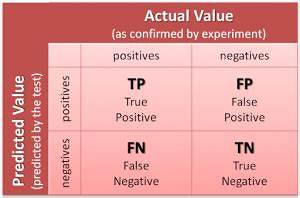
Confusion matrix for a binary classification
Dans ce cas, la variable à estimer peut prendre deux valeurs : Positive ou Négative. Les colonnes représentent la classe réelle de la valeur explicative, tant dis que les rangées correspondent à la classe estimée.
Mesures de classification
Une fois que la matrice de confusion a été établit, elle peut être utilisée pour des mesures plus approfondies afin d’obtenir une meilleure évaluation de la qualité du modèle. Parmi les mesures de classification, on trouve la accuracy, la précision, le rappel, la spécificité et le score F1.
a. Accuracy
La accuracy correspond au nombre de prédictions correctes faites par le modèle. Elle représente le ratio entre le nombre de prédictions correctes et le nombre total de prédiction. Ceci peut être calculé en utilisant les valeurs de la matrice de confusion et en utilisant la formule suivante :

Cette mesure est utilisée lorsque le nombre de True Positive et de True Negative sont les plus important.
b. Précision (ou Precision)
La précision correspond au nombre d’éléments corrects rendus par le modèle. En d’autres termes, cela correspond au ratio entre le nombre de classifications positives correctes et le nombre total de prédiction positives. Elle peut être calculée avec la formule suivante :

Cette mesure est utilisée lorsque le nombre de False Positive est le plus élevé.
c. Rappel (ou Recall)
Le rappel détermine la proportion des valeurs positives qui ont été prédites avec précision. Cette mesure correspond donc au ratio entre le nombre de prédictions positives correctes et le nombre total de classifications de classe positive. On peut utiliser la formule suivante :

On utilise cette mesure lorsque le nombre de False Negative est le plus important.
d. Spécificité (ou Specificity)
La spécificité correspond au nombre de classes négatives prédites par le modèle. Cette mesure est déterminée par le ratio entre le nombre de prédictions négatives correctes et le nombre total de prédictions négatives. Elle peut se calculer de la manière suivante :

e. Score F1 (ou F1 score)
Le score F1 correspond à une combinaison des mesures de rappel et de précision. Cette mesure est utilisée lorsqu’une distinction claire ne peut pas être faite entre ces deux mesures ou lorsque les False Negative et False Positive sont les plus important.

A venir
Ainsi, nous avons exploré les différentes mesures qui peuvent être utilisées pour évaluer la qualité de la performance d’un modèle de classification. Pour chaque application, l’utilisateur doit choisir une mesure à utiliser, dépend de son problème.
Maintenant que nous avons compris ce processus d’évaluation, nous allons explorer les principaux algorithmes de classification dans les deux prochains articles : Principaux algorithmes de classification – Partie 1 et Principaux algorithmes de classification – Partie 2.