L’apprentissage non supervisé est l’une des branches du machine learning. Il identifie des clusters ou des groupes en fonction de données non-étiquetées, avec très peu d’intervention humaine. Dans l’article précédent, nous avons analysé les deux principales catégories de modèles non supervisés, soit le clustering et les règles d’association, ainsi que les principales applications de ces modèles. Veuillez consulter cet article si vous souhaitez en savoir plus sur ces sujets. Maintenant, nous allons nous concentrer sur les principaux algorithmes, utilisés dans certaines applications.
Principaux algorithmes d’apprentissage non supervisé
a. Méthode des K-moyennes
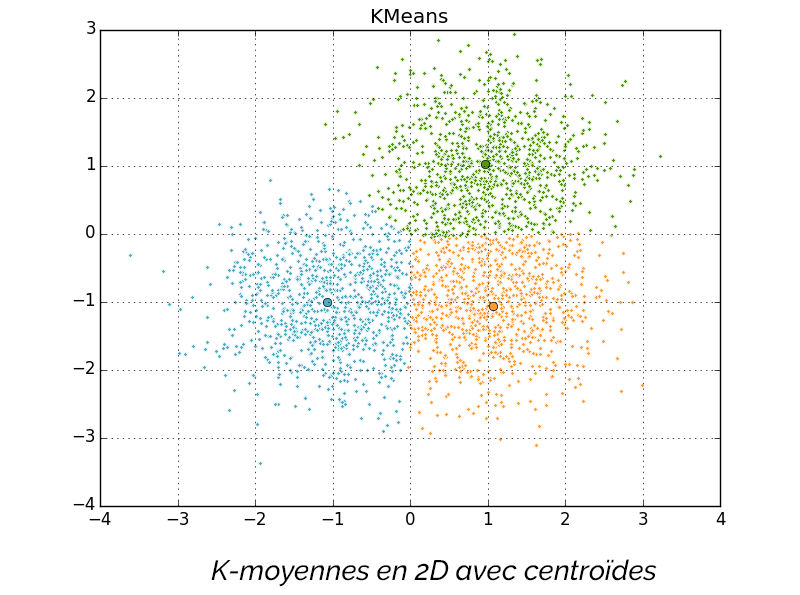
La méthode des K-moyennes, ou K-means clustering, est l’un des algorithmes de clustering les plus utilisés. Dans cette méthode, les points de données sont assignés à K groupes. Dans ce cas, K représente le nombre de groupes créés en fonction de la distance entre le noyau de chaque groupe. Ce noyau est aussi appelé le centroïde et est soit choisi au hasard, soit spécifié par le data scientist, en fonction des données. Une fois que le nombre de groupes (K) et les centroïdes ont été identifiés, la modèle assigne chaque nouveau point au noyau le plus proche et le groupe dans le cluster correspondant. La méthode la plus répandue pour calculer la distance entre un point et un noyau est le carré de la distance Euclidienne.
L’un des principaux défis avec la méthode des K-moyennes est le fait que le nombre de clusters doit être spécifié avant le début du modèle. Ceci peut être compliqué par moment, surtout lorsque la quantité de données est très importante. Si une grande valeur pour K est choisie, le modèle rendra de plus petits groupes. A l’inverse, si K prend une petite valeur, alors le modèle rendra des grands groupes.
Cette méthode est la plus souvent utilisée pour la classification de documents, la segmentation d’images et la segmentation marketing.
b. Clustering hiérarchique
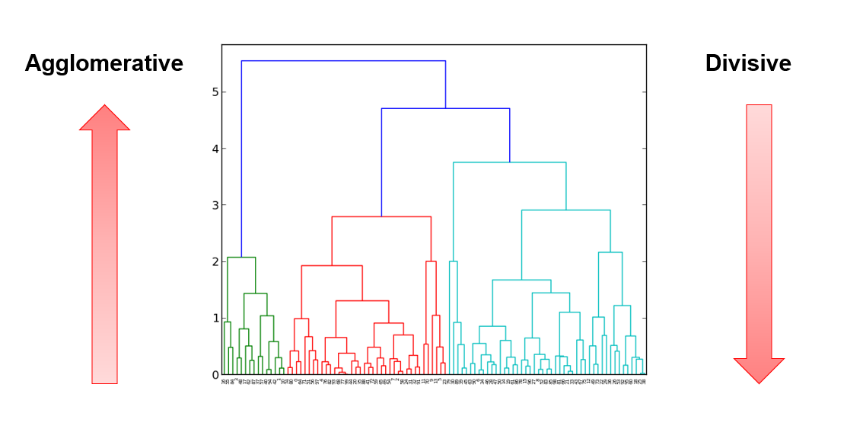
Le clustering hiérarchique, ou hierarchical clustering, est un autre algorithme de clustering, qui créé une structure s’apparentant à un arbre. On appelle cette structure un dendrogramme. Ce type de clustering peut être divisé en deux catégories : les classifications descendantes hiérarchiques et les classifications ascendantes hiérarchiques. Dans le cas d’une classification descendante hiérarchique, tous les points commencent par être assignés à un même groupe puis, lorsque le modèle est affiné, les points sont séparés en clusters jusqu’à ce qu’il y est un cluster pour chaque point. A l’inverse, dans le cas d’une classification ascendante hiérarchique, chaque point commence par être considéré comme son propre groupe puis, lorsque le modèle est affiné, des paires de clusters sont combinés, en fonction de leurs similarités, en un grand groupe contenant toutes les observations.
Comme pour la méthode des K-moyennes, les mesures de distances sont utilisées pour évaluer la similarité entre les points. Il existe quatre principales méthodes pour mesurer la similarité :
i) Single linkage
Dans cette méthode, la distance entre deux clusters correspond à la distance minimale entre deux points de chaque cluster :
ii) Complete linkage
Dans cette deuxième méthode, la distance entre deux clusters correspond à la distance maximale entre deux points de chaque cluster :
iii) Average linkage
Dans cette troisième méthode, la distance entre deux clusters correspond à la moyenne des distances entre toutes les paires de points dans chaque groupe :
iv) Ward’s linkage
Dans cette quatrième méthode, la distance entre deux clusters correspond à l’augmentation de la somme des carrés, après que chaque cluster a été combiné. Le but est de minimiser la variance totale entre clusters.
Dans ces quatre méthodes, la distance Euclidienne est la mesure d’évaluation la plus utilisée pour calculer les distances entre points.
c. Algorithme Apriori
L’algorithme Apriori est l’un des algorithmes d’apprentissage non supervisé, qui peut être classifié comme une règle associative. En effet, cette technique utilise une approche ascendante, dans laquelle les points ou les collections de points les plus fréquents sont identifiés et utilisés pour établir des règles d’association. Cet algorithme est basé sur l’idée qu’un sous-groupe d’un groupe fréquent est également un groupe fréquent.
Les algorithmes Apriori ont gagné en popularité lorsqu’ils ont commencé à être utilisé pour l’analyse du panier de consommation ou pour les recommandations musicales dans les applications les plus répandues. En effet, cet algorithme permet d’établir la probabilité qu’un individu achète ou écoute un élément X sachant que il/elle a acheté ou écouté l’élément Y. Ainsi, ce modèle nécessite les comportements passés d’un individu afin de faire des prédictions sur les comportements futurs.
d. Analyse en composantes principales (ACP)
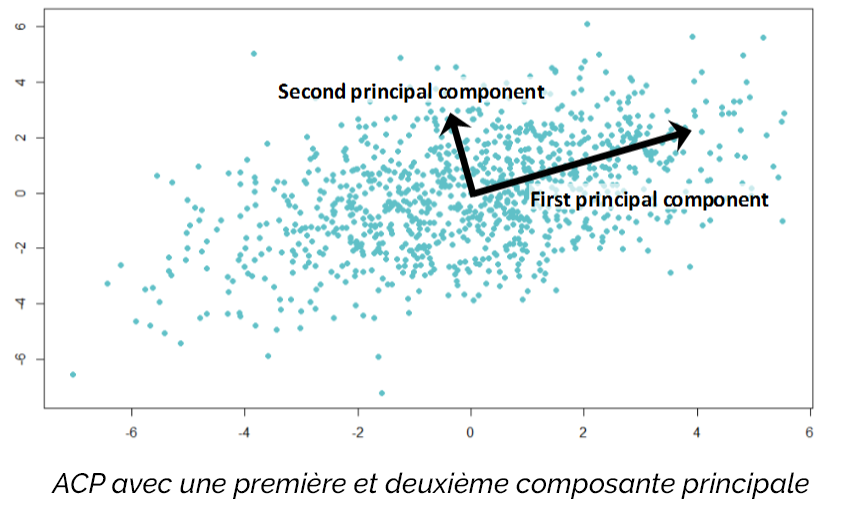
L’analyse en composante principale (ACP), ou Principal Component Analysis (PCA), est une méthode de réduction dimensionnelle. Cette technique permet de réaliser des modèles prédictifs avec très peu de perte d’informations. Pour cela, elle transforme un groupe de variables corrélées et trouve le groupe sous-jacent de variables orthogonales avec la plus grande variance. En d’autres termes, cette méthode utilise le système de coordonnées d’un groupe de données afin d’en trouver un nouveau par translations et rotations.
Contrairement à d’autres modèles, l’ACP rend un vecteur, à la place d’une fonction, ce qui implique qu’il peut représenter n’importe quelle sorte de groupe de données et aide à visualiser les données à haute dimension.
De surcroît, étant donné que l’ACP est une méthode de réduction dimensionnelle, elle a pour but d’identifier les paramètres formateurs de schéma au sein des données. Les paramètres qui influencent ce phénomène sont appelés les « composantes principales ». La première composante principale correspond à la direction qui maximise la variance au sein des données, alors que la seconde composante principale maximise aussi la variance mais est orthogonale à la première. Chaque composante principale ajoutée sera orthogonale à la composante précédente avec la plus grande variance.
e. Décomposition en valeurs singulières (SVD)
La décomposition en valeurs singulières, ou single value decomposition (SVD), est une autre méthode de réduction dimensionnelle. Elle décompose une matrice X en un produit de trois matrices : , où :
est une matrice diagonale de n-par-p, contenant des nombres positifs nommés les valeurs singulières de X.
est une matrice orthogonale de n-par-n, dont les colonnes sont des vecteurs orthogonaux de longueur n, appelés les vecteurs singuliers gauche de X
W est une matrice orthogonale de p-par-p, dont les colonnes sont des vecteurs orthogonaux, appelés les vecteurs singuliers droit de X.
Comme pour l’ACP, cette méthode est souvent utilisée pour réduire le bruit et la dimension d’un groupe de données.
A venir
Ainsi, une variété de différents algorithmes d’apprentissage non supervisé existe. Ils peuvent être choisis en fonction du problème et évalués en utilisant les mesures d’évaluation, comme celles présentées dans l’article Apprentissage supervisé et Classification.
Nous espérons que cet article vous aura donné une bonne compréhension des algorithmes. Si vous souhaitez en savoir plus sur les applications de l’apprentissage non supervisé, veuillez consulter l’article précédent.





 , où :
, où : est une matrice diagonale de n-par-p, contenant des nombres positifs nommés les valeurs singulières de X.
est une matrice diagonale de n-par-p, contenant des nombres positifs nommés les valeurs singulières de X. est une matrice orthogonale de n-par-n, dont les colonnes sont des vecteurs orthogonaux de longueur n, appelés les vecteurs singuliers gauche de X
est une matrice orthogonale de n-par-n, dont les colonnes sont des vecteurs orthogonaux de longueur n, appelés les vecteurs singuliers gauche de X