L’apprentissage non supervisé est une branche du machine learning, caractérisée par l’analyse et le regroupement de données non-étiquetées. Pour cela, ces algorithmes apprennent à trouver des schémas ou des groupes dans les données, avec très peu d’intervention humaine. En termes mathématiques, l’apprentissage non supervisé implique l’observation de plusieures occurrences d’un vecteur X and l’apprentissage de la probabilité de distribution p(X) pour ces occurrences.
Cette méthode est en contraste avec l’apprentissage supervisé, dans lequel le modèle reçoit des données d’entrainement étiquetées, à partir desquelles il doit apprendre. Ainsi, les modèles d’apprentissage supervisé et non supervisé diffèrent sur la base de leurs données d’entrée. En effet, un modèle d’apprentissage supervisé utilise des données d’entrée et de sortie étiquetées, alors qu’un modèle d’apprentissage non supervisé apprend à partir de données d’entrainement non-étiquetées, afin de faire des prédictions sur la classification des points. Par conséquent, avec un modèle d’apprentissage non supervisé, le but est d’obtenir un aperçu à partir d’une grande quantité de données, contrairement à un modèle d’apprentissage supervisé, pour lequel le but est de prédire la valeur de sortie pour de nouvelles données.
Si vous souhaitez en savoir plus sur l’apprentissage supervisé et ses différentes méthodes, veuillez consulter les articles précédents dédiés à ce sujet.
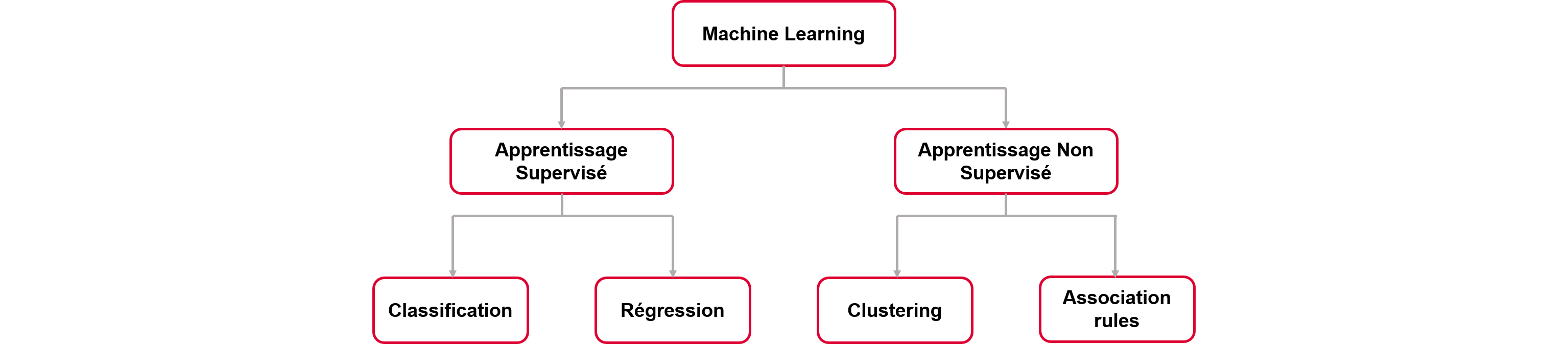
Décomposition du machine learning
Deux types de problèmes d’apprentissage non supervisé
On peut considérer l’apprentissage non supervisé comme étant séparé en deux catégories : le clustering et l’association.
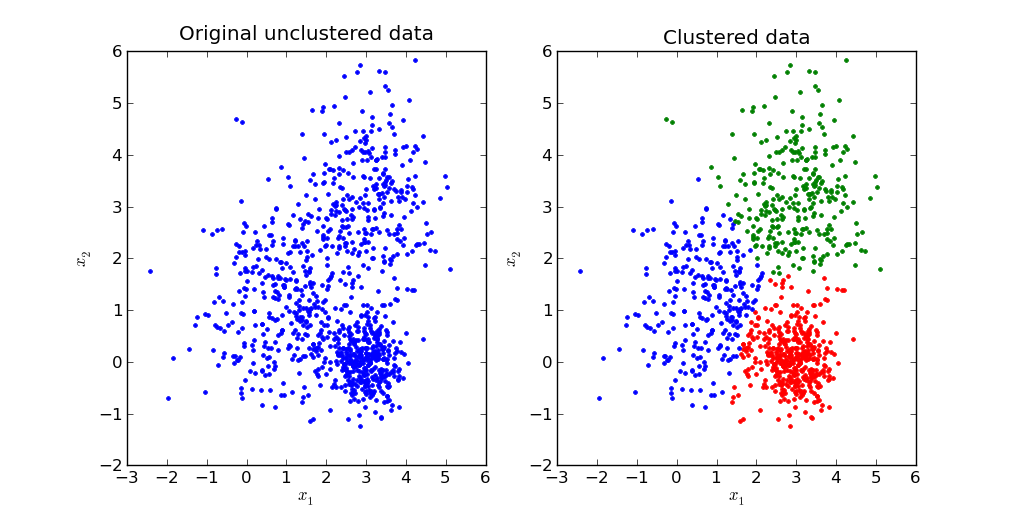
Le clustering est une technique d’apprentissage non supervisé, qui groupe des données non-étiquetées en fonction de leurs similarités and de leurs différences. Ainsi, les points sont rassemblés dans des groupes (ou des clusters) de telle manière à ce que les points au sein d’un même groupe soient le plus similaire possible, pendant que les points dans des groupes différents soient les plus différents possible. Pour cela, une analyse de cluster identifie les caractéristiques, au sein des données, et groupe les points en fonction de la présence ou de l’absence de ces caractéristiques. Parmi les méthodes de clustering, on trouve la méthode des k-moyennes (ou k-means), la classification hiérarchique (ou hierarchical clustering) ou encore la classification probabilistique (ou probabilistic clustering).
D’un autre côté, les règles d’association sont une autre forme d’apprentissage non supervisé, qui identifie une relation entre les points de données. En d’autres termes, ces algorithmes trouvent les points qui apparaissent ensemble dans les données. Ces méthodes sont souvent utilisées pour l’analyse du panier de consommation, qui permet aux compagnies de comprendre la relation entre l’achat de différents produits. En effet, cela permet d’établir une relation de la forme suivante : « Les individus qui achètent le produit X ont également tendance à acheter le produit Y ». Parmi les algorithmes d’association, on trouve l’algorithme Apriori, l’algorithme Eclat et l’algorithme FP-growth.
Il existe divers algorithmes d’apprentissage non supervisé que nous allons explorer dans le prochain article.
Applications de l’apprentissage non supervisé
Malgré le fait que l’apprentissage non supervisé a tendance à être plus difficile d’utilisation, cette méthode reste néanmoins utilisée pour diverses applications.
a. Détection d’anomalies dans la finance
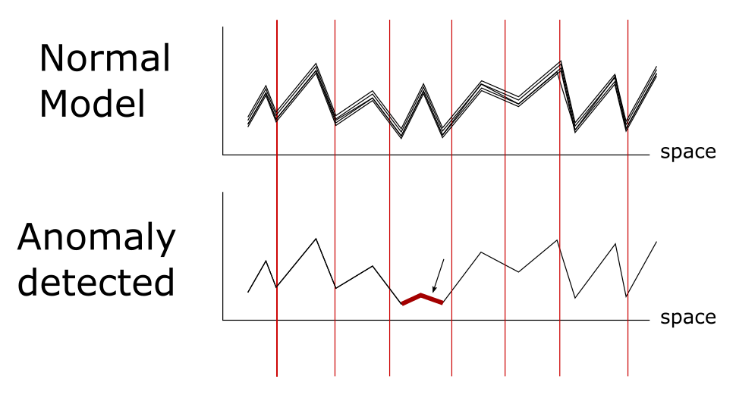
Les algorithmes d’apprentissage non supervisé ont la capacité d’analyser d’importantes quantités de données et d’identifier les points inhabituels au sein de ces données. Une fois que ces anomalies ont été détectées, elles peuvent être mises en avant au près de l’utilisateur, qui peut décider d’y donner suite ou non. La détection d’anomalies peut se montrer très utile dans les secteurs financiers et banquiers. En effet, les fraudes financières sont devenues un problème quotidien, du fait de la simplicité avec laquelle les informations bancaires d’individus peuvent être obtenues. En utilisant l’apprentissage non supervisé, les transactions frauduleuses ou non-autorisées, faites sur un compte bancaire, sont identifiées étant donné qu’elles vont constituer une anomalie au sein du schéma régulier du client.
Pour cela, un algorithme de détection d’anomalies peut être utilisé. Ce modèle reçoit l’historique bancaire d’un individu, qui inclut le type de transaction, le montant des transactions, l’heure et la localisation des transaction, etc. En utilisant toutes ces informations, le modèle peut identifier si une transaction est frauduleuse en fonction de si elle se détache, ou non, des autres transactions réalisées par cet individu. Après avoir reçu l’alerte, la banque peut informer ce client de cette détection et lui apporter des conseils sur les démarches à suivre.
Aujourd’hui, de nombreuses banques, comme Bank of America, utilisent des modèles de détection d’anomalies afin d’assurer la sécurité des informations des leurs clients.
La détection d’anomalies peut également avoir d’autres applications comme pour l’identification d’erreurs humaines ou des défaillances de sécurité.
b. Clustering de données médicales
Dans le domaine médical, de grandes quantités de données non-étiquetées sont disponibles. Dans ce domaine, l’apprentissage non supervisé est privilégié car l’étiquetage des données médicales peut se montrer très coûteux, en termes de temps et d’argent. Ainsi, les modèles de clustering peuvent être très utiles pour la détection, la segmentation et la classification d’image. En effet, les algorithmes de clustering peuvent recevoir une grande quantité de données et identifier des groupes ou des schémas au sein de ces informations, chose qui pourrait être très difficile pour un professionnel.
Par exemple, un algorithme d’apprentissage non supervisé peut être utilisé sur des données de maladies neurologiques afin d’identifier les facteurs menant à une maladie ou des sous-groupes correspondant aux différentes étapes d’une maladie.
c. Moteurs de recommandations et publicité personnalisées
En utilisant l’apprentissage non supervisé, un modèle peut recevoir un achat ou l’historique d’achat d’un individu et l’utiliser pour identifier des schémas et faire des prédictions. Ainsi, des compagnies peuvent utiliser ce type de modèle pour mettre au point des stratégies de vente adaptées et des publicités ciblées, en fonction de des données d’un individu.
De nombreuses autres applications d’apprentissage non supervisé existent et permettent d’identifier des schémas et des groupes au sein de données. Ceci ne pourrait pas être réalisé de manière efficace par un individu. Par exemple, ces algorithmes sont utilisés par Google News et Apple News pour grouper les articles traitant du même sujet mais provenant de diverses sources.
A venir
Nous espérons que cet article vous aura donné une bonne compréhension de l’apprentissage non supervisé et certaines de ces applications.
Comme vous l’avez surement compris, les modèles d’apprentissage supervisé et non supervisé ont leurs propres applications dépendant du résultat souhaité. Dans l’article suivant, nous explorerons les différents algorithmes d’apprentissage non supervisé : la méthode des k-moyennes, la classification hiérarchique et l’algorithmes Apriori.