La classification est au cœur des principaux produits de Linedata. Comme nous l’avons expliqué dans l’article précédent, l’apprentissage supervisé permet de prédire une valeur dépendante en fonction d’une valeur indépendante. Pour cela, l’algorithme apprend à partir de données d’entrainement étiquetées et permet, par la suite, d’appliquer les règles acquises et de généraliser sur des valeurs d’essai.
Un problème de classification nécessite que la valeur dépendante prédite soit une classe ou une catégorie, contrairement à un problème de régression où la valeur à prédire est continue. De plus, diverses méthodes de classification et de régression peuvent être appliquées dépendant du problème à traiter. Pour en savoir plus sur ces différents algorithmes, nous vous invitons à consulter nos précédents articles publiés sur le site de Linedata.
Maintenant, nous allons nous concentrer sur les scores d’erreur de transaction, l’une des applications de la classification dans notre compagnie.
Score d’erreur de transaction : l’un des cas d’usage de la classification
Chez Linedata, nous utilisons différentes méthodes de machine learning pour améliorer l’efficacité de nos produits. Une application importante est celle des scores d’erreur de transaction.
En effet, afin d’améliorer notre compréhension du marché, il est parfois très utile de regarder les analyses post-transactionnelles d’un système. Pour cela, on peut faire face à une quantité importante de données, qui fournissent tout un historique de transactions. En utilisant ces données, nous pouvons analyser les transactions précédentes, qui ont été entrées dans le système, et déterminer celles qui ont été modifiées et celles qui ne l’ont pas été. Ces changements peuvent être le résultat d’une erreur humaine ou opérationnelle.
En utilisant l’historique des transactions, il peut être intéressant de prédire si une future transaction sera modifiée ou non. En effet, on peut calculer la probabilité, ou « score d’erreur », d’une transaction entrante. Cela correspondrait à la probabilité de cette transaction d’être modifiée ou non, durant sa durée de vie.
Pour cela, nous utilisons un modèle de classification, basé sur N échantillons, qui correspondent à N transactions qui se sont produites dans le passé. Afin d’entrainer le modèle, nous divisons, de manière aléatoire, les données en deux groupes : les données d’entrainement et celles de test. Chaque groupe comprend des points de donnée avec un valeur indépendant X et une classe de sortie Y.
Pour ce problème, les paramètres de la variable X sont initialement établit à partir des données transactionnelles, telles que le type de transaction ou la monnaie de transaction. Les paramètres de X sont par la suite améliorés pour inclure une combinaison des activités de transaction et du marché, qui sont obtenues en combinant les informations transactionnelles avec les indicateurs du marché, qui sont par la suite attachées à chaque transaction.
Concernant la classe de sortie, nous faisons face à une prédiction binaire, étant donné que la variable de sortie peut correspondre à l’une des deux catégories : « modifiée » ou « non modifiée ».
Ainsi, l’algorithme va généraliser et établir des règles en fonction des données d’entrainement. Par la suite, il pourra prédire la catégorie d’une nouvelle transaction, en fonction des paramètres de celle-ci. De plus, une probabilité ou un score d’erreur est fourni pour chaque transaction.
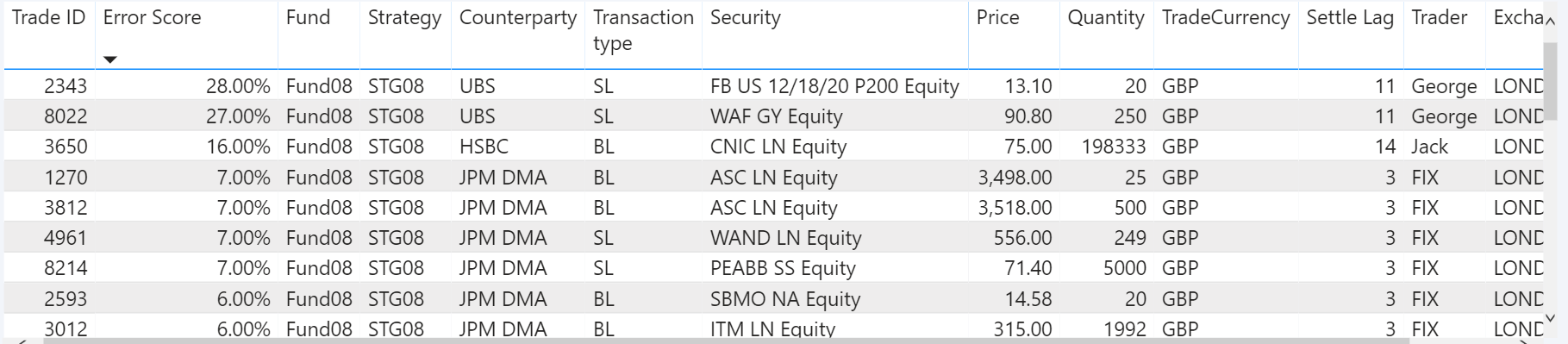
Les résultats de ce modèle sont présentés sont forme tabulaire ci-dessous :
Afin de construire ce modèle, nous avons utilisé la libraire sklearn de Python, qui permet de séparer les données en un groupe d’entrainement et un groupe de test, avec une séparation par défaut de 75% entrainement et 25% test. A partir de cette même libraire, la classification extra-trees montre de bons résultats pour ce modèle. Cette méthode implante un méta-estimateur, qui construit un certain nombre d’arbres décisionnels aléatoires à partir des données. Par la suite, elle calcule une moyenne des précisions prédites et contrôle le surapprentissage. Ci-dessous, vous pouvez trouver une présentation de cette méthode.
Pour en savoir plus sur les arbres de décision et les forêts d’arbres décisionnels, veuillez consulter les articles précédents sur les principaux algorithmes de classification.
A venir
Nous espérons que cet article, ainsi que les précédent, vous auront donné une bonne compréhension de l’apprentissage supervisé et de ses utilisations chez Linedata.